More pages: 1 ...
11 ...
13 14 15 16 17 18
19 20 21 22 23 ...
31 ...
41 ...
48
Classic Internet memes
Sunday, April 5, 2009 | Permalink
All the good ones. Hamster Dance, All You Base, Star Wars Kid, you name it. Everything's been documented in chronological order on
this webpage.
Naturally it's a bit more dense in the recent years, but it's nice to see emoticons back in 1982 as well if you scroll past some empty space.

[
1 comments |
Last comment by Michael (2009-04-08 21:43:50) ]
Yay! New GPU!
Friday, April 3, 2009 | Permalink
It's good to have friends in the industry.
When my GPU was confirmed dead I replaced it with the only GPU I had laying around that would even produce an image on my screen, which was an old GF 6600 that I used as a debug device for Nvidia specific issues in my demos. While it produced an image it was only able to drive it in a double-pixel mode (1280x800, native is 2560x1600), which was kind of painful and not a state I wanted to be in for longer than necessary. So the first thing I did was to order a new GPU, a HD 4870. However, it didn't take long until I was offered a new GPU, first from AMD and then from Nvidia. So I cancelled the order and waited for the free GPUs instead.
Meanwhile I've been coding a little in double-pixel mode the last two weeks. So now my next framework works on DX9 cards in D3D_FEATURE_LEVEL_9_3 through DX11. Not sure how much of that I will maintain in the future, but I suppose there could be cases where I want a demo to run on older hardware. I've also spent some more time playing around with SSE, moving on to my image class, which I'm also building around SSE. Haven't done much with it yet, but at least I've done a couple of routines for swapping BGRA to RGBA and mipmap generation. SSSE3 has a very convenient instruction for BGRA8 to RGBA8 swapping called pshufb, with which I can swap 4 pixels per instruction. I'm using SSE3 (with just two 'S'es) as the baseline though, so I have also implemented a standard path, which was trickier to do, but 4 pixels in 5 instructions is not bad either.
Now the AMD card has arrived, so I'm back to normal again. It's a HD 4890, which is very nice, especially since it was free.
I haven't had much chance to play around with it yet. I've tried a couple of games and that's about it so far. But this weekend I'm gonna be coding.
[
5 comments |
Last comment by Humus (2009-04-05 00:56:24) ]
Recommended reading
Sunday, March 29, 2009 | Permalink
The
Visual C++ Team Blog sometimes has some of the longest blog posts that you can imagine. However, they contain loads of detailed and very useful information. I highly recommend these two posts that contain info about the C++0x standard and what's being implemented in MSVC, and why you should care. And yes, you should care. Especially rvalue references can have a significant performance advantage if you do it right.
Lambdas, auto, and static_assert: C++0x Features in VC10, Part 1
Rvalue References: C++0x Features in VC10, Part 2[
4 comments |
Last comment by yoav (2009-04-06 18:31:49) ]
Random google result
Saturday, March 28, 2009 | Permalink
Why hasn't Nvidia marketed
this product more?
[
4 comments |
Last comment by ABC (2009-06-01 08:26:45) ]
OpenGL 3.1 released
Wednesday, March 25, 2009 | Permalink
Press Release
Specification[
5 comments |
Last comment by Overlord (2009-03-27 20:31:16) ]
New DirectX SDK
Tuesday, March 24, 2009 | Permalink
The DirectX March 2009 release has been released.
Download here[
4 comments |
Last comment by Humus (2009-03-25 21:33:49) ]
For dust thou art ...
Sunday, March 22, 2009 | Permalink
... and unto dust shalt thou return.
In loving memory (1GB) of my Radeon HD 3870x2 who passed away this afternoon.

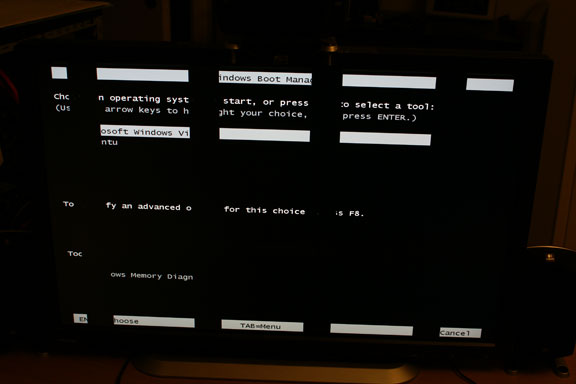

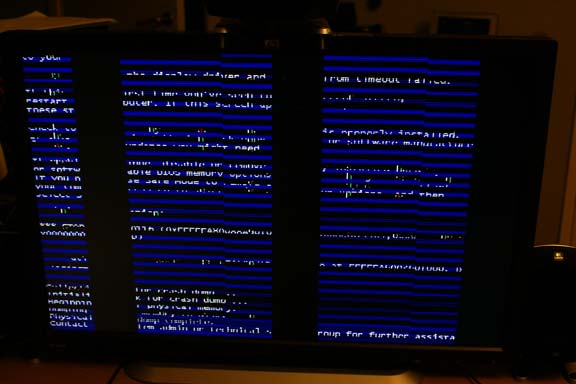
After suffering experimental code, beta SDKs and many driver resets for a long time, it finally couldn't handle it anymore. It walked many code paths that no one walked before.
It was 1.2 years old.
Rest in peace.
[
12 comments |
Last comment by Humus (2009-04-04 17:42:02) ]
A couple of benchmarks
Saturday, March 21, 2009 | Permalink
So I put my SSE vector class to the test to see if it would give any actual performance improvement over the standard C++ implementation I've used in the past. So I set up a test case with an array of 16 million random float4 vectors, which I multiplied with a matrix and stored into result array of the same size.
First I tested the diffent implementations against each other. I tested the code compiled to standard FPU code, and then with MSVC's /arch:SSE2 option enabled, which uses SSE2 code instead of FPU most of the time (although mostly just uses scalar instructions), and then my own implementation using SSE intrinsics. This is the time it took to complete the task:
FPU: 328ms
SSE2: 275ms
Intrisics: 177ms
That's a decent performance gain. I figured there could be some performance gain by unrolling the loop and do four vectors loop iteration.
Unroll: 165ms
Quite small gain, so I figured I'm probably more memory bandwidth bound than computation limited. So I added a prefetch and streaming stores just to see how that affected performance.
Prefetch: 164ms
Stream: 134ms
Prefetch + Stream: 128ms
Final code runs 2.56x faster than the original. Not too bad.
[
6 comments |
Last comment by Paul (2011-02-01 21:48:29) ]
More pages: 1 ...
11 ...
13 14 15 16 17 18
19 20 21 22 23 ...
31 ...
41 ...
48

