More pages: 1 ...
11 ...
15 16 17 18 19 20
21 22 23 24 25 ...
31 ...
41 ...
48
Shader programming tips #3
Monday, February 9, 2009 | Permalink
Multiplying a vector by a matrix is one of the most common tasks you do in graphics programming. A full matrix multiplication is generally four float4 vector instructions. Depending on whether you have a row major or column major matrix, and whether you multiply the vector from the left or right, the result is either a DP4-DP4-DP4-DP4 or MUL-MAD-MAD-MAD sequence.
In the vast majority of the cases the w component of the vector is 1.0, and in this case you can optimize it down to three instructions. For this to work, declare your matrix as row_major. If you previously was passing a column major matrix you'll need to transpose it before passing it to the shader. You need a matrix that works with mul(vertex, matrix) when declared as row_major. Then you can do something like this to accomplish the transformation in three MAD instructions:
float4 pos;
pos = view_proj[2] * vertex.z + view_proj[3];
pos += view_proj[0] * vertex.x;
pos += view_proj[1] * vertex.y;
It should be mentioned that vs_3_0 has a read port limitation, and since the first line is using two different constant registers, HLSL will put a MOV instruction in there as well. But the hardware can be more flexible (for instance ATI cards are). In vs_4_0 there's no such limitation and HLSL will generate a three instruction sequence.
[
0 comments ]
Ceiling cat is watching me code
Sunday, February 8, 2009 | Permalink
I can has ceiling cat? Yez I can! Also, I can has stikky fingurz from all teh glouh.



Paper model available
here. Print, glue and attach to ceiling.

[
6 comments |
Last comment by phillyx (2009-03-01 23:29:38) ]
Shader programming tips #2
Wednesday, February 4, 2009 | Permalink
Closely related to what I mentioned in tips #1, it's of great importance to use parantheses properly. HLSL and GLSL evaluate expressions left to right, just like C/C++. If you're multiplying vectors and scalars together the number of operations generated may differ a lot. Consider this code:
float4 result = In.color.rgba * In.intensity * 1.7;
This will result in the color vector being multiplied with the intensity scalar, which is 4 scalar operations. The result is then multipled with 1.7, which is another 4 scalar operations, for a total of 8. Now try this:
float4 result = In.color.rgba * (In.intensity * 1.7);
Intensity is now multiplied by 1.7, which is a single operation, and then the result is multiplied with color, which is 4, for a total of five scalar operations. A save of three instructions by merely placing parantheses in the code.
Shouldn't the compiler be smart enough to figure this thing out by itself? Not really. HLSL will sometimes merge constants when it considers this safe to do. However, when dealing with variables that have values with unknown range the compiler cannot make the assumption that multiplying in another order will give the same result. For instance 1e-20 * 1e30 * 1e10 will result in 1e20 if you multiply left to right, whereas 1e-20 * (1e30 * 1e10) will result in an overflow and return INF.
In general I recommend that you even place parantheses around compile-time constants to make sure the compiler merge them when appropriate.
[
1 comments |
Last comment by ruysch (2010-01-02 16:32:38) ]
Epic fail
Sunday, February 1, 2009 | Permalink
I was sent a link to this blog by a co-worker recently:
I Get Your Fail
High recognition factor for anyone in game development.
And good entertainment even if you're not.
[
1 comments |
Last comment by dvoid (2009-02-01 14:32:28) ]
Shader programming tips #1
Thursday, January 29, 2009 | Permalink
DX9 generation hardware was largely vector based. The DX10 generation hardware on the other hand is generally scalar based. This is true for both ATI and Nvidia cards. The Nvidia chips are fully scalar, and while the ATI chips still have explicit parallelism the 5 scalars within an instruction slot don't need to perform the same operation or operate on the same registers. This is important to remember and should affect how you write shader code. Take for instance this simple diffuse lighting computation:
float3 lightVec = normalize(In.lightVec);
float3 normal = normalize(In.normal);
float diffuse = saturate(dot(lightVec, normal));
A normalize is essentially a DP3-RSQ-MUL sequence. DP3 and MUL are 3-way vector instructions and RSQ is scalar. The shader above will thus be 3 x DP3 + 2 x MUL + 2 x RSQ for a total of 17 scalar operations.
Now instead of multiplying the RSQ values into the vectors, why don't we just multiply those scalars into the final scalar instead? Then we would get this shader:
float lightVecRSQ = rsqrt(dot(In.lightVec, In.lightVec));
float normalRSQ = rsqrt(dot(In.normal, In.normal));
float diffuse = saturate(dot(In.lightVec, In.normal) * lightVecRSQ * normalRSQ);
This replaces two vector multiplications with two scalar multiplications, saving us a 4 scalar operations. The math savvy may also recognize that rsqrt(x) * rsqrt(y) = rsqrt(x * y). So we can simplify it to:
float lightVecSQ = dot(In.lightVec, In.lightVec);
float normalSQ = dot(In.normal, In.normal);
float diffuse = saturate(dot(In.lightVec, In.normal) * rsqrt(lightVecSQ * normalSQ));
We are now down to 12 operations instead of 17. Checking things out in
GPU Shader Analyzer showed that the final instruction count is 5 in both cases, but the latter shader leaves more empty scalars which you can fill with other useful work.
It should be mentioned that while this gives the best benefit to modern DX10 cards it was always good to do these kind of scalarizations. It often helps older cards too. For instance on the R300-R580 generation it often meant more instructions could fit into the scalar pipe (they were vec3+scalar) instead of utilizing the vector pipe.
[
1 comments |
Last comment by sqrt[-1] (2009-01-31 14:32:40) ]
Custom alpha to coverage
Sunday, January 25, 2009 | Permalink
In DX10.1 you can write a custom sample mask to an SV_Coverage output. This nice little feature hasn't exactly received a lot of media coverage (haha!). Basically it's an uint where every bit tells to which samples in the multisample render target the output will be written to. For instance if you set it to 0x3 the output will be written to samples 0 and 1, and leave the rest of the samples unmodified.
What can you use it for? The most obvious thing is to create a custom alpha-to-coverage. Alpha-to-coverage simply converts the output alpha into a sample mask. If you can provide a better sample mask than the hardware, you'll get better quality. And quite frankly, the hardware implementations of alpha-to-coverage hasn't exactly impressed us with their quality. You can often see very obvious and repetitive dither patterns.
So I made a simple test with a pseudo-random value based on screen-space position. The left image is the standard alpha-to-coverage on an HD 3870x2, and on the right my custom alpha-to-coverage.


[
4 comments |
Last comment by Dr Black Adder (2011-10-14 01:08:17) ]
Drawbacks of modern technology
Saturday, January 24, 2009 | Permalink
CRT monitors have been out of fashion for a while now, and while they took a lot more desk space than the modern flat screens they had one important advantage: you could put stuff on top of them.
So I just got myself a nice 5.1 system for my computer:

The sound is great and all, but the problem is I have no place to put my center speaker. My monitor has a frame that's less than 5 cm (2") thick, and that's on a 30" monitor. I'd need about the double for the speaker to stand stably. I can hardly be the first one to have this problem, but oddly enough after spending the whole day going from one electronics shop to another and even going to Ikea and the likes I found no product for mounting anything on top of a LCD screen. Not even google seems to come up with anything useful. Back in the CRT days there were products for turning the top of a monitor into a shelf, even though often the screen itself was good enough for things like a center speaker. For now I've simply put some screws through the holes and just let them hang in front of the monitor, which should at least keep it from sliding backwards. Not a particularly pretty or safe solution, but at least it's standing there now.
[
6 comments |
Last comment by Humus (2009-01-29 19:25:41) ]
Triangulation
Wednesday, January 14, 2009 | Permalink
When you look at a highly tessellated model it's generally understood that it will be vertex processing heavy. Not quite as widely understood is the fact that increasing polygon count also adds to the fragment shading cost, even if the number of pixels covered on the screen remains the same. This is because fragments are processed in quads. So whenever a polygon edge cuts through a 2x2 pixel area, that quad will be processed twice, once for both of the polygons covering it. If several polygons cut through it, it may be processed multiple times. If the fragment shader is complex, it could easily become the bottleneck instead of the vertex shader. The rasterizer may also not be able to rasterize very thin triangles very efficiently. Since only pixels that have their pixel centers covered (or any of the sample locations in case of multisampling) are shaded the quads that need processing may not be adjacent. This will in general cause the rasterizer to require additional cycles. Some rasterizers may also rasterize at fixed patterns, for instance an 4x4 square for a 16 pipe card, which further reduces the performance of thin triangles. In addition you also get overhead because of less optimal memory accesses than if everything would be fully covered and written to at once. Adding multisampling into the mix further adds to the cost of polygon edges.
The other day I was looking at a particularly problematic scene. I noticed that a rounded object in the scene was triangulated pretty much as a fan, which created many long and thin triangles, which was hardly optimal for rasterization. While this wasn't the main problem of the scene it made me think of how bad such a topology could be. So I created a small test case to measure the performance of three different layouts of a circle. I used a non-trivial (but not extreme) fragment shader.
The most intuitive way to triangulate a circle would be to create a fan from the center. It's also a very bad way to do it. Another less intuitive but also very bad way to do it is to create a triangle strip. A good way to triangulate it is to start off with an equilateral triangle in the center and then recursively add new triangles along the edge. I don't know if this scheme has a particular name, but I call it "max area" here as it's a greedy algorithm that in every step adds the triangle that would grab the largest possible area out of the remaining parts on the circle. Intuitively I'd consider this close to optimal in general, but I'm sure there are examples where you could beat such a strategy with another division scheme. In any case, the three contenders look like this:
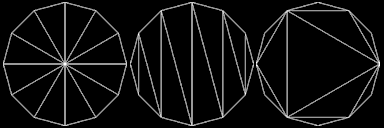
And their performance look like this. The number along the x-axis is the vertex count around the circle and the y-axis is frames per second.
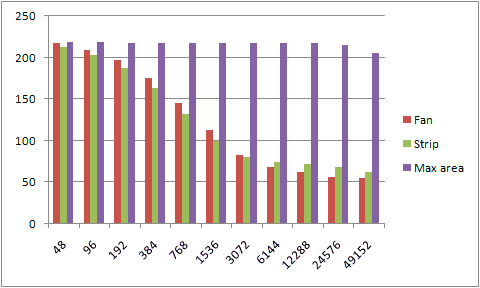
Adding multisampling into the mix further adds to the burden with the first two methods, while the max area division is still mostly unaffected by the added polygons all the way across the chart.
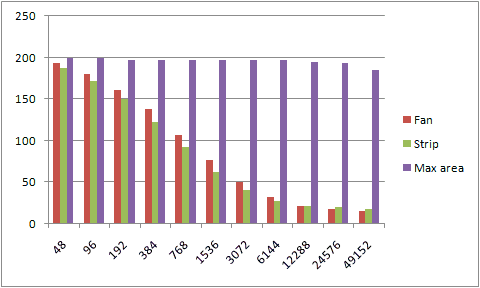
[
34 comments |
Last comment by Deface (2025-06-05 14:28:44) ]
More pages: 1 ...
11 ...
15 16 17 18 19 20
21 22 23 24 25 ...
31 ...
41 ...
48

